2026 年 3 月 31 日,Anthropic 的 Claude Code CLI 完整源码因 npm 包中的
.map文件泄露。512,000 行 TypeScript,1,900 个文件——这不是一个 CLI 工具,这是一个藏在终端里的 AI Agent 运行时。
为什么要读这份源码?
市面上的 AI 编程工具不少:Cursor、Windsurf、Aider、Copilot CLI……但 Claude Code 是第一个被完整泄露源码的生产级 Agent Runtime。它不是一个简单的"调 API → 输出结果"的 wrapper——它有自己的渲染引擎、权限系统、多 Agent 协调器、五层记忆体系、四级上下文压缩,甚至还有投机执行机制。
读懂它,不只是在看 Anthropic 的内部工程,而是在看一个完整的 Agent 架构范本。
本系列共 12 篇,本篇是全景导读。
技术栈:一个看似奇怪的组合
| 层级 | 选型 | 为什么? |
|---|---|---|
| 运行时 | Bun | 启动速度是 CLI 体验的生命线。Bun 比 Node.js 快 3-5 倍。bun:bundle 的 feature() API 实现编译期死代码消除——未启用的功能从构建产物中彻底消失 |
| 语言 | TypeScript (strict) | 50 万行代码没有类型系统是不可想象的 |
| 终端 UI | React + 自定义 Ink | 声明式 UI + Yoga flexbox 布局,在终端里实现接近 IDE 的交互体验 |
| CLI 解析 | Commander.js | 成熟稳定,类型安全 |
| Schema | Zod v4 | 一套 Schema 同时用于运行时验证和 API JSON Schema 生成 |
| 搜索 | ripgrep | 代码搜索的事实标准 |
| 协议 | MCP + LSP | 标准协议集成外部工具和语言服务 |
| 遥测 | OpenTelemetry | 标准化可观测性 |
| 特性门控 | GrowthBook | 灰度发布、A/B 测试 |
这套组合的底层逻辑是:启动要快(Bun)、交互要好(React+Ink)、扩展要广(MCP/LSP)、安全要硬(TypeScript strict + Zod)。

值得注意的是,Claude Code 完全不依赖传统的代码索引——没有 Embedding 向量检索,没有 AST 分析,没有代码图谱。它纯靠大模型的推理能力配合 Grep/Glob 全局搜索来理解代码库。这是一个大胆的哲学选择:赌模型能力的增长速度会超过代码库的增长速度。
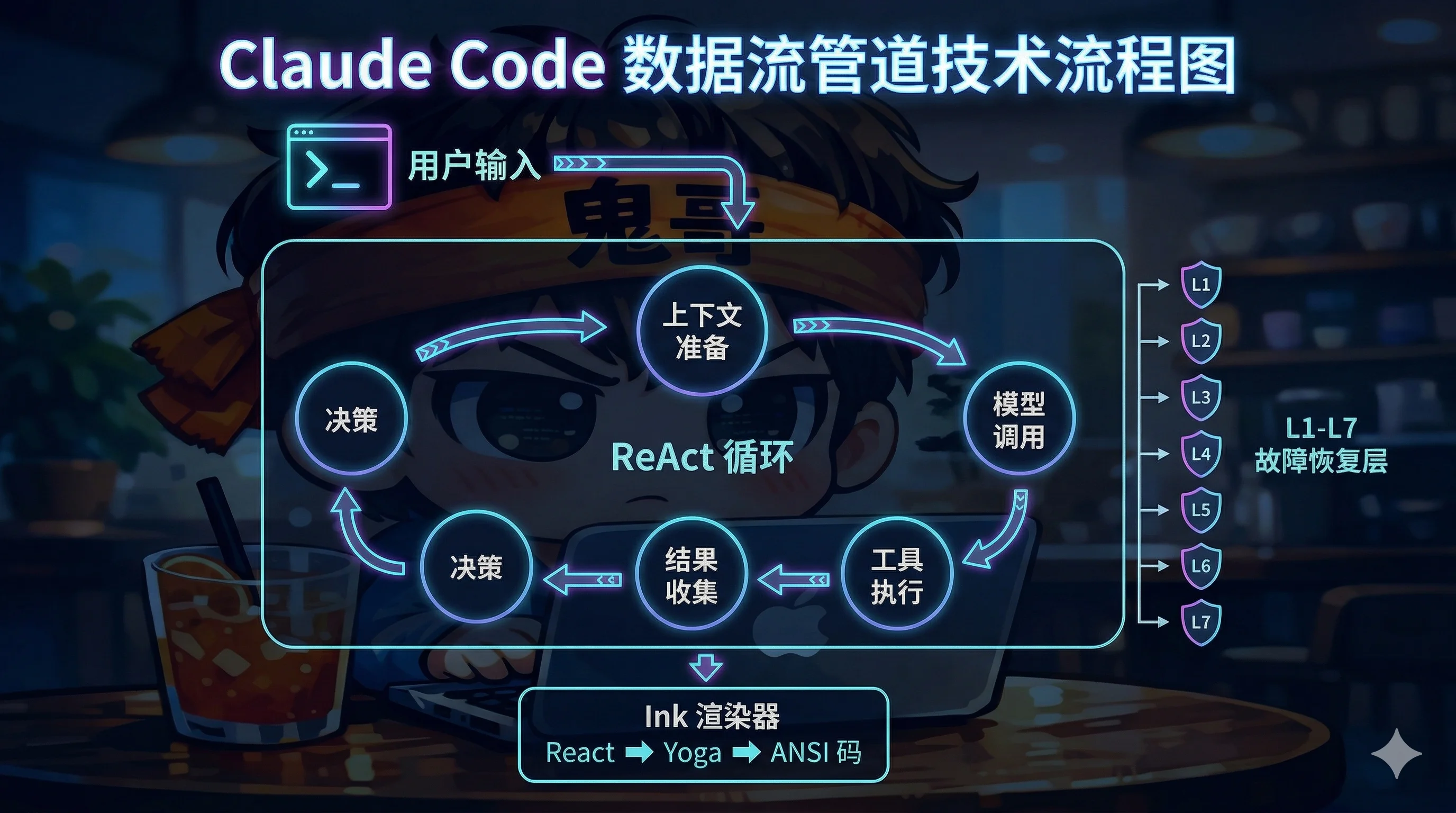
核心数据流:一次对话背后发生了什么
当你在 Claude Code 中输入一条消息,数据会经过以下管线:
| |
这个流程最值得注意的是:
模型调用和工具执行是并行的 ——
StreamingToolExecutor在模型还在输出时就已经开始执行已完成解析的工具调用。这不是等模型说完再跑工具,而是流水线式并行。七层恢复不是简单重试 —— 每一层处理不同类型的故障。413 上下文溢出会触发压缩后重试;输出被截断会自动将 Token 上限从 8K 升至 64K;API 过载会指数退避。系统在各种异常下自我修复,而不是直接崩溃。
上下文压缩是分级的 —— 不是简单地"砍掉旧消息",而是四级递进:轻量裁剪 → 缓存感知压缩 → AI 全量摘要 → 紧急压缩。每一级都尽可能保留更多有用信息。
五个维度看系统成熟度
维度一:ReAct 循环 — 系统心脏
query.ts 中的 while(true) 循环是整个系统的心脏,实现了经典的 ReAct(推理-行动)模式。
五个阶段,每轮都走一遍:
| 阶段 | 做什么 | 关键技术 |
|---|---|---|
| 上下文准备 | 裁剪旧消息、压缩工具结果 | Snip + Microcompact + Autocompact 三级组合 |
| 模型流式调用 | 发送对话历史 + 系统提示 + 工具列表 | 流式输出、Prompt Cache 分割 |
| 工具执行 | 并行执行工具调用 | StreamingToolExecutor 流水线并行 |
| 附件收集 | 任务通知、记忆提取、文件变更 | 后台 Agent 异步提取记忆 |
| 终止决策 | 根据模型行为决定循环或结束 | 七层恢复、Stop Hook |
最精巧的设计在于流式工具执行器:模型还在生成第二个工具调用时,第一个工具已经在并行执行了。如果第一个工具是并发安全的(isConcurrencySafe: true),它甚至可以和其他并发安全工具同时运行。
七层恢复机制则是韧性设计的典范:

| 层 | 触发条件 | 恢复策略 |
|---|---|---|
| L1 | 对话达到上下文窗口 80% | 预警式自动摘要 |
| L2 | 历史消息过长 | 轻量裁剪(Snip) |
| L3 | 工具结果冗余 | 缓存感知压缩(Microcompact) |
| L4 | API 返回 413 | 选择性消息归档(Context Collapse) |
| L5 | L4 失败 | 紧急全量压缩(Reactive Compact) |
| L6 | 输出被截断 | Token 上限 8K→64K 单次升级 |
| L7 | L6 仍被截断 | 注入恢复指令,最多重试 3 次 |
系列第 2 篇将深入拆解这个循环的每个阶段和恢复机制。
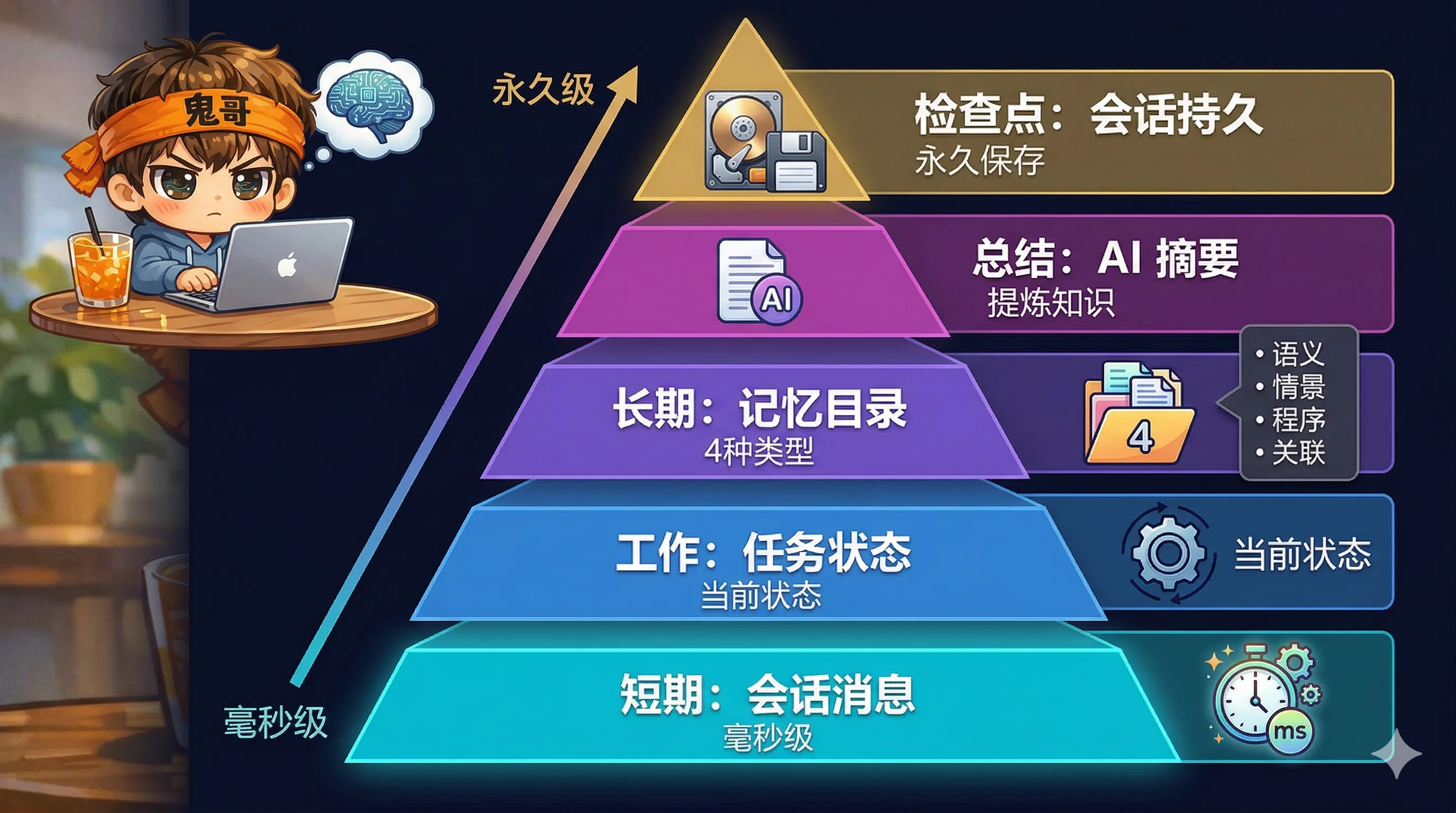
维度二:五层记忆体系 — 超越上下文窗口
大多数 Agent 工具的"记忆"就是对话历史。Claude Code 构建了五层记忆体系,覆盖从毫秒到永久的全时间尺度:
| |
长期记忆的设计尤其精巧:它不是一个笨重的向量数据库,而是本地目录下的 markdown 文件,按主题组织。检索时不是做 embedding 相似度搜索,而是把所有记忆的文件名和描述发给模型,让模型选出最相关的 5 个再读取全文。
这种"用 LLM 做检索"的方式看似低效,但在记忆数量可控(几十到几百个文件)的场景下非常实用——它避免了 embedding 模型的维护成本,同时利用了大模型的语义理解能力。
系列第 5 篇将深入拆解五层记忆体系。
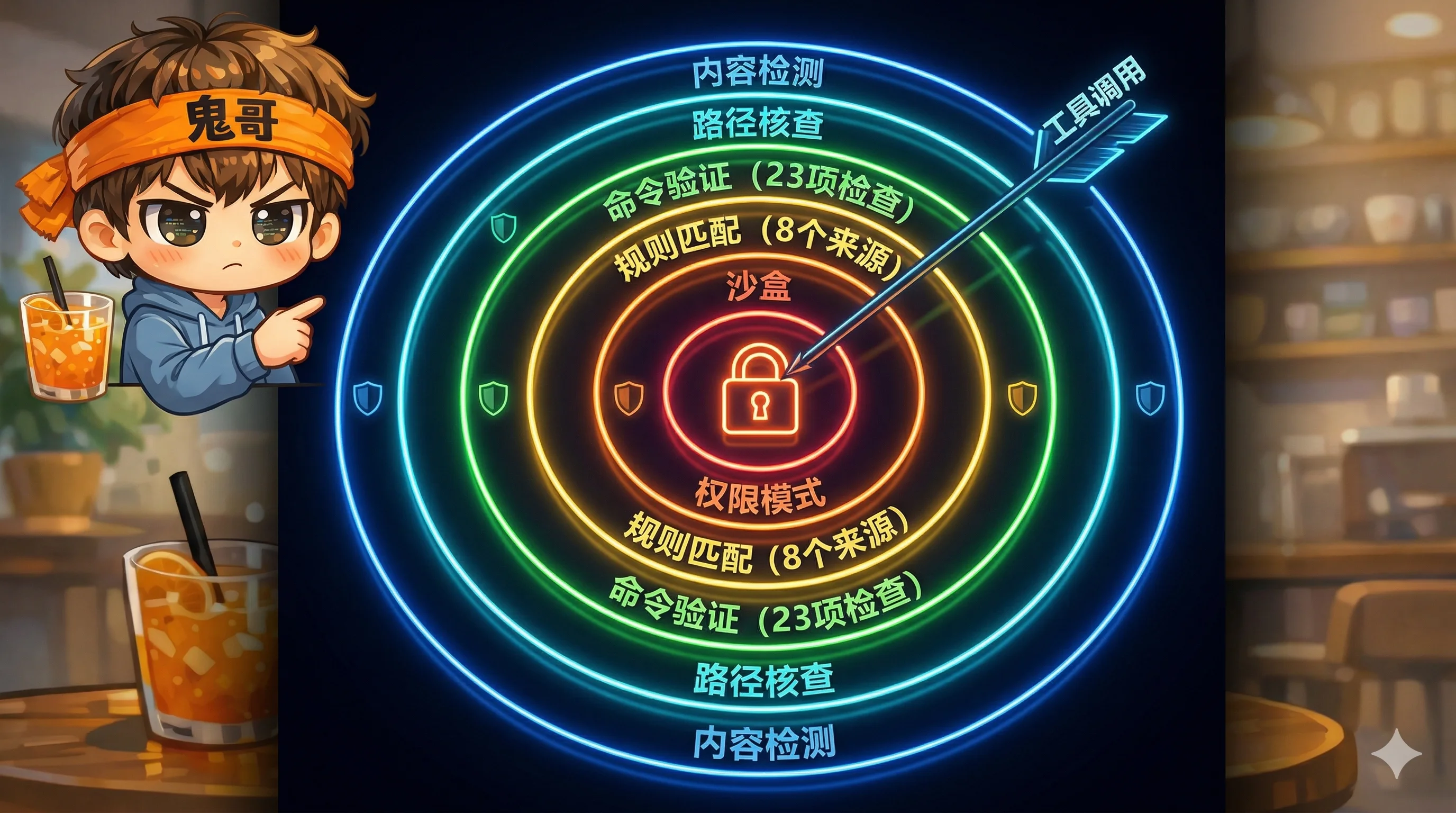
维度三:安全纵深 — 六层防御,不信任任何输入
一个能执行 Shell 命令的 AI Agent,安全不是可选项,是生存条件。Claude Code 构建了六层纵深防御:
| |
几个硬核细节:
- 纯 TypeScript 写的 Bash 解析器(130KB):生成 tree-sitter-bash 兼容的 AST,在执行前静态分析命令安全性。设置了 50ms 超时和 50K 节点预算,防止恶意构造的命令消耗解析资源。
- 23 项 Bash 安全检查:覆盖命令替换、注入攻击、Unicode 同形攻击、IFS 注入、brace 展开、heredoc 注入等攻击面。
- 解释器黑名单:Python、Node 等只允许
--version检查,禁止在自动模式下执行任意脚本。 - ZSH 危险命令黑名单:16 个可绕过安全检查的 Zsh 内建命令(zmodload、emulate、sysopen、zpty 等)被显式禁止。
这套体系的设计哲学是每一层都不信任上一层——即使沙箱被绕过,权限系统仍然在拦截;即使权限被绕过,Bash 解析器仍然在检查命令安全性。
系列第 6 篇将深入拆解完整的安全体系。
维度四:多 Agent 编排
Claude Code 不是单 Agent 工具。它支持三种 Agent 执行模型和一个编排层:
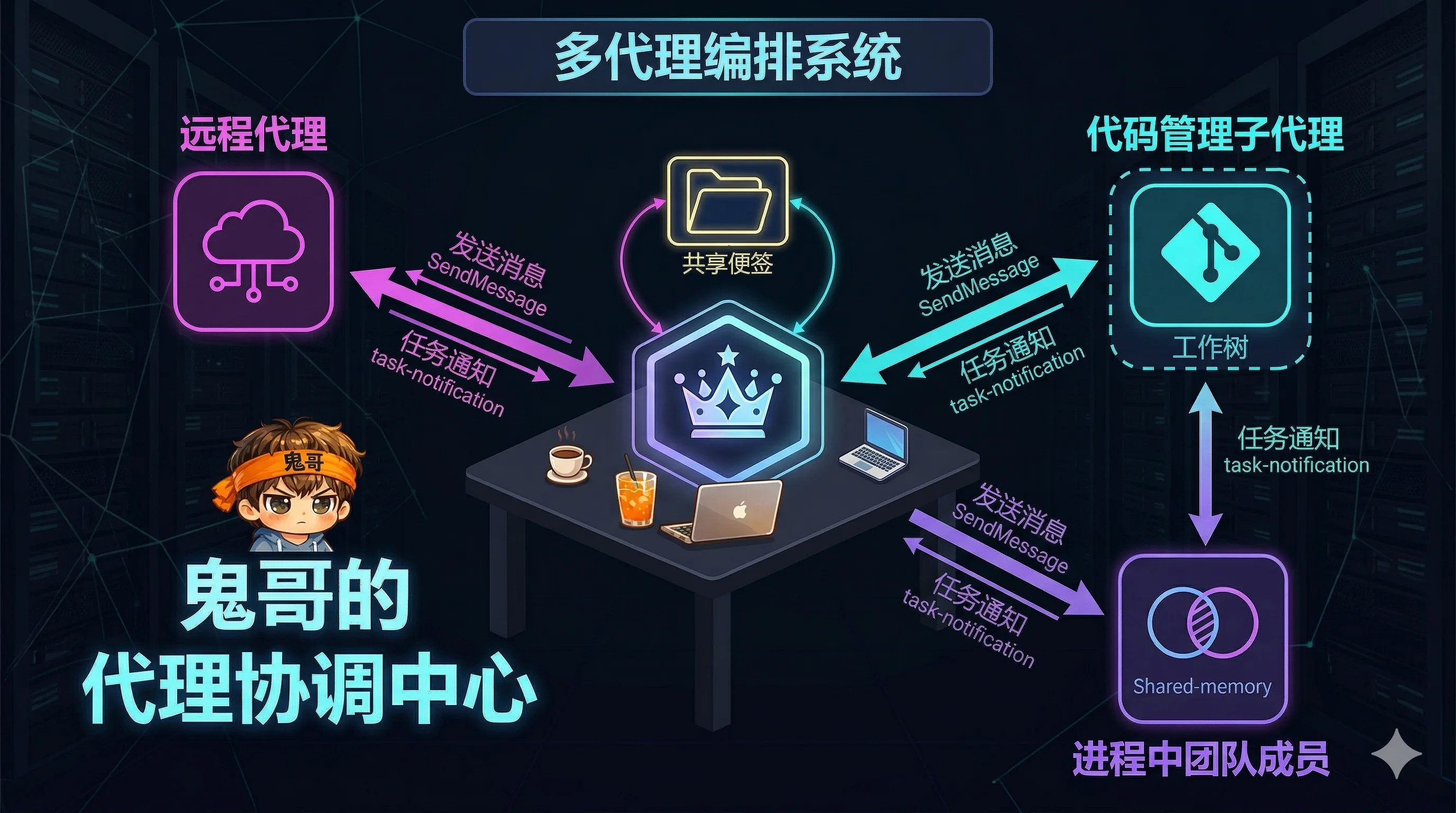
三种执行模型:
| 模型 | 实现 | 隔离方式 | 适用场景 |
|---|---|---|---|
| 子 Agent | AgentTool 生成 | Git Worktree | 独立的文件修改任务 |
| 同进程队友 | InProcessTeammateTask | AsyncLocalStorage | 需要共享内存的协作 |
| 远程队友 | RemoteAgentTask | 独立进程/远程会话 | PR 审查、后台任务 |
Coordinator 模式:
当启用后,系统切换为"指挥者-执行者"架构:
- Coordinator 只负责任务分解和结果汇聚
- Worker 拥有完整工具集,独立执行
- 内置角色:General Purpose(通用)、Explore(只读探索)、Plan(只读规划)、Verification(破坏性验证)
- Worker 间通过
SendMessageTool通信,通过 Scratchpad 目录共享持久知识 - 任务完成后以
<task-notification>XML 标签的 user-role 消息通知 Coordinator
Git Worktree 隔离是一个精巧的设计:每个子 Agent 在独立的 Git Worktree 中工作,可以自由修改文件而不影响主工作区。用户确认后才合并变更;拒绝则直接删除 worktree。
系列第 8 篇将深入拆解多 Agent 架构。
维度五:可观测性与隐私
遥测栈:OpenTelemetry(Trace + Metrics + Logs)→ OTLP/Prometheus/BigQuery
三级隐私类型系统——这是最值得学习的设计之一:
| |
类型名本身就是安全检查:当你写 AnalyticsMetadata_I_VERIFIED_THIS_IS_NOT_CODE_OR_FILEPATHS 时,这个冗长的类型名逼迫你在写代码时思考:“我确认这个值不包含代码或文件路径吗?” 这是把安全审查嵌入类型系统的优雅做法。
MCP 工具名默认脱敏为 'mcp_tool',只有官方注册的 MCP 服务器才保留原始名称。工具输入截断到 512 字符/4KB,防止业务代码意外被遥测上传。
六大惊艳的工程设计(速览)
| # | 设计 | 核心思路 | 详见 |
|---|---|---|---|
| 1 | Prompt 缓存分割 | 系统提示拆为静态(全局缓存)+ 动态(不缓存),极大提高 API 缓存命中率 | 第 3 篇 |
| 2 | 四级上下文压缩 | Snip → Microcompact → Autocompact → Reactive Compact,压缩后智能恢复关键信息 | 第 3 篇 |
| 3 | 投机执行 | 在用户确认前,在 Overlay 文件系统中预执行。确认写入,拒绝丢弃 | 第 7 篇 |
| 4 | 23 项 Bash 安全检查 | 覆盖注入、替换、同形攻击等。解释器黑名单防止自动执行脚本 | 第 6 篇 |
| 5 | 自研状态管理 | Zustand 风格轻量 Store,精准订阅防止 React Ink 级联重渲染 | 第 7 篇 |
| 6 | 工具延迟加载 | 超过 20 个工具时,不直接写入 system prompt,让模型自己搜索发现 | 第 4 篇 |
模块地图
| |
一个关键哲学选择
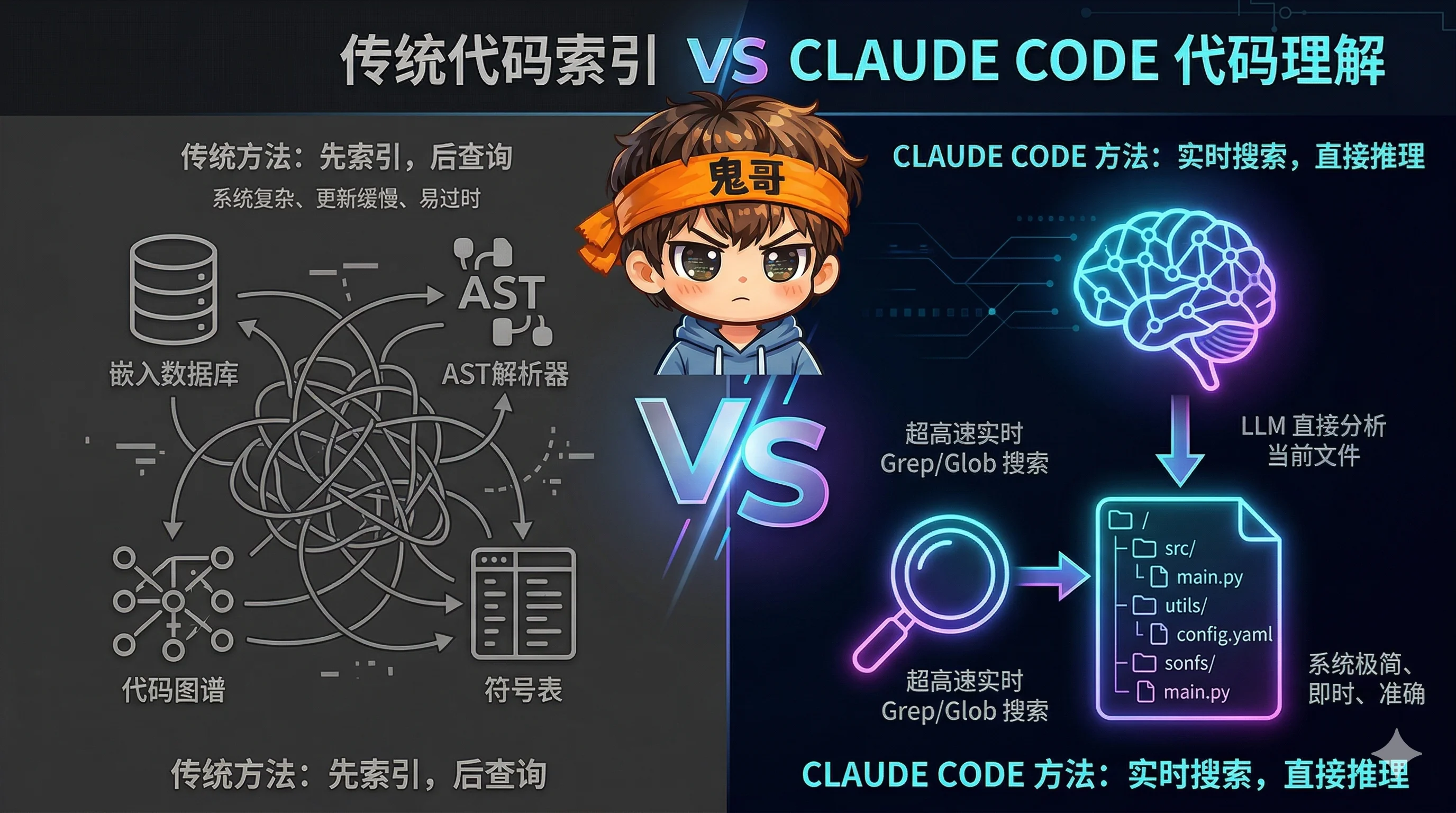
最后值得讨论一个贯穿整个架构的哲学选择:Claude Code 完全不做代码索引。
没有 Embedding 向量数据库,没有 AST 解析,没有代码图谱,没有符号表。当模型需要理解一个代码库时,它就用 GrepTool 和 GlobTool 全局搜索。
这意味着:
- 冷启动零成本——不需要先索引再使用
- 永远是最新的——每次搜索都读实际文件
- 简单到不可能出错——没有索引就没有索引过期
但也意味着:
- 大型代码库可能效率低——每次搜索都是全局扫描
- 依赖模型的推理能力——需要模型知道搜什么、怎么缩小范围
- Token 消耗更高——搜索结果直接进入上下文
这个选择在当前模型变强的趋势下是说得通的。模型越强,越擅长用最少的搜索找到目标。但在百万行级代码库中,这个策略是否还能 hold 住,是一个开放问题。
系列导航
| 篇 | 标题 | 核心问题 |
|---|---|---|
| 01 | 512K 行代码,一个终端里的 Agent Runtime(本篇) | 全景认知 |
| 02 | ReAct 循环:while(true) 里的五个阶段与七层恢复 | 系统心脏怎么跳 |
| 03 | Prompt 缓存分割与四级上下文压缩 | 长对话怎么省钱 |
| 04 | 50 个工具的统一契约:Tool System 设计 | Agent 能力怎么扩展 |
| 05 | 五层记忆体系:从短期到持久化 | Agent 怎么记住事情 |
| 06 | 纵深防御:23 项安全检查与"不信任任何输入" | 怎么让 Agent 安全 |
| 07 | 投机执行与自研状态管理:隐藏延迟的两个利器 | 怎么让用户感觉快 |
| 08 | 多 Agent 编排:三种执行模型与 Coordinator 模式 | 多个 Agent 怎么协作 |
| 09 | 在终端里造一个浏览器:自定义 Ink 渲染引擎 | 终端 UI 怎么做到 60fps |
| 10 | Bridge 与协议层:让 VS Code、Web、Mobile 共享一个 Claude | CLI 怎么变成平台 |
| 11 | Skill、Plugin、Hook:三层扩展的设计谱系 | 怎么不改源码就扩展 |
| 12 | 回顾:从 Claude Code 中提炼的 10 个 Agent 工程模式 | 带走什么 |
下一篇,我们将深入 query.ts 中的 while(true) 循环,看看这个 Agent Runtime 的心脏是如何一拍一拍跳动的。