
看累了听个音乐吧
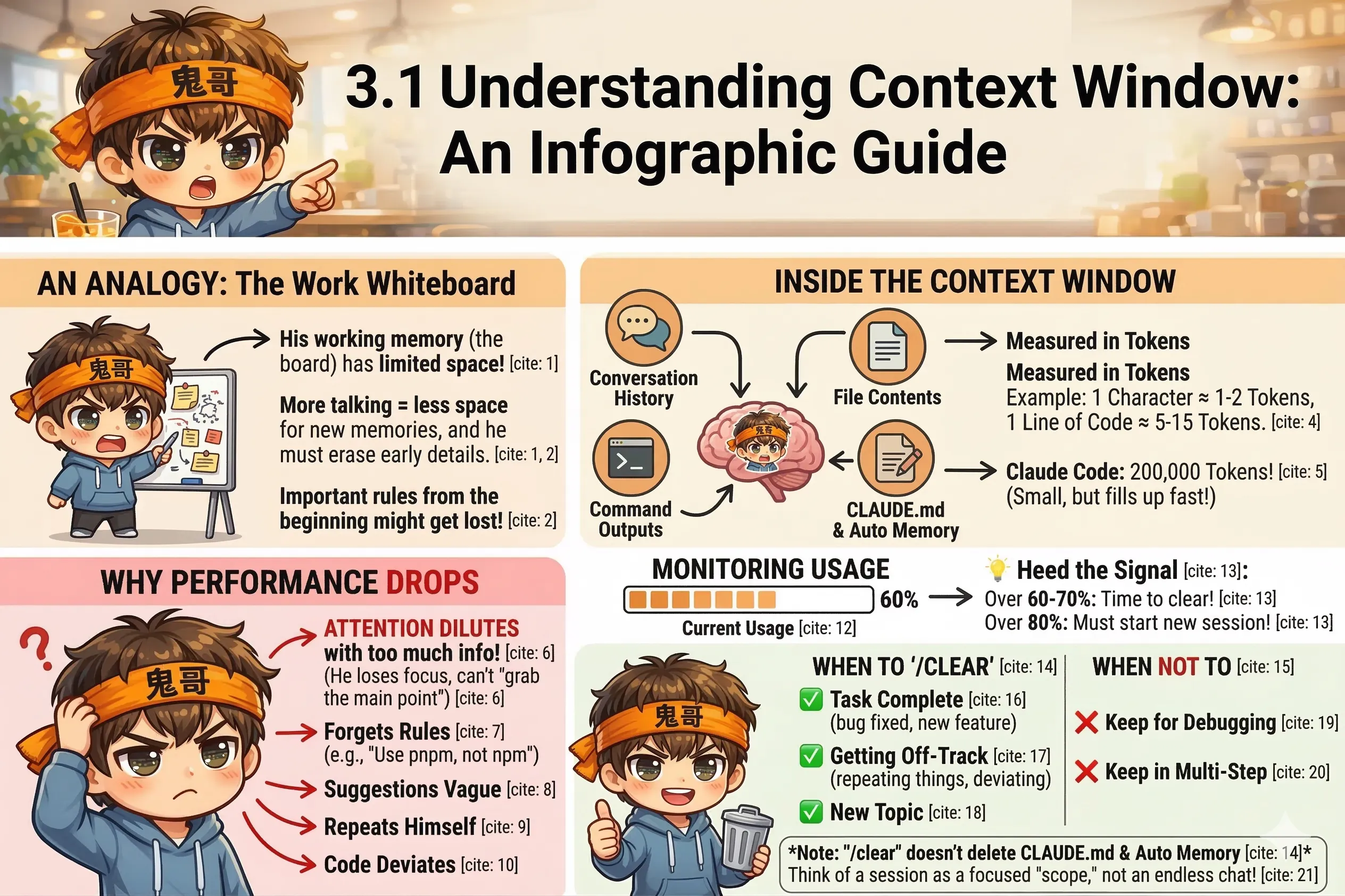
想象你正在和一位记忆力很好但工作记忆有限的同事协作。
他能记住对话里说过的每一句话——但他的大脑只有一张固定大小的白板。你们聊得越多,白板越满。当白板快满的时候,他开始不得不擦掉最早写的内容,腾出位置记新的东西。
结果是:你在对话开头说的那些重要规则,他可能已经记不清了。
这就是上下文窗口的工作方式。
Claude Code 每次会话都有一个上下文窗口,里面装着:
这些加在一起,用 token 来计量。一个汉字大约是 1-2 个 token,一行代码大约是 5-15 个 token。
Claude Code 的上下文窗口是 20 万 token,听起来很大——但一个中等规模的代码库加上一个调试过程,几万 token 就没了。
上下文窗口有一个不太直觉的特性:填得越满,性能越差。
这不是空间不够用的问题,而是 AI 模型在处理超长上下文时,注意力会被稀释。简单说:东西太多了,它会"抓不住重点"。
常见的症状:
一旦出现这些情况,基本就是上下文该清了的信号。
在 Claude Code 会话里,底部状态栏会实时显示当前上下文用量:
[■■■■■□□□□□] 45% | 89,432 tokensClaude Code 还提供了一个自定义状态栏的功能(通过 /statusline 命令),可以显示更详细的信息。
💡 经验参考:超过 60-70% 就要开始注意了;超过 80% 建议考虑清空或开新会话。
/clear /clear 命令会清空当前对话历史,但不会清掉 CLAUDE.md 和 Auto Memory——下次对话开始时,它们还是会自动加载。
建议在这些时机 /clear:
不建议 /clear 的时机:
把 Claude Code 的会话想成一次工作任务的范围,而不是一个一直开着的聊天窗口。
任务开始 → 做完 → /clear → 下一个任务。
这样每次对话都在一个干净、聚焦的上下文里,效果会明显好于一个越来越长的"万能会话"。
下一节,我们来看如何用 CLAUDE.md 给每次会话打好基础,让它不需要你每次都重新介绍项目。